简介
Stable Diffusion(以下简称SD)是一个深度学习模型。
SD最为人熟知的应用莫过于“文生图”,简单来说:就是输入一段文字即可返回和文本内容匹配的图像。
当然,SD也可以用来做图生图、图片修复、图片超分辨率(放大)等任务。
对于普通人而言,最简单的上手方式就是通过stable-diffusion-webui下载运行(以下简称sd-webui)。
sd-webui提供了低门槛快速上手SD模型的可视化平台,不过需要注意的是,由于SD任务计算复杂度较大,一般需在GPU环境下安装运行,具体安装教程可参考官网。
以下就是生成的一张机器人图,参数配置如下,BotFlow公众号的头像就是这么来的:)
1 | clean background, best quality, 8k, cute bot, baymax, smile |
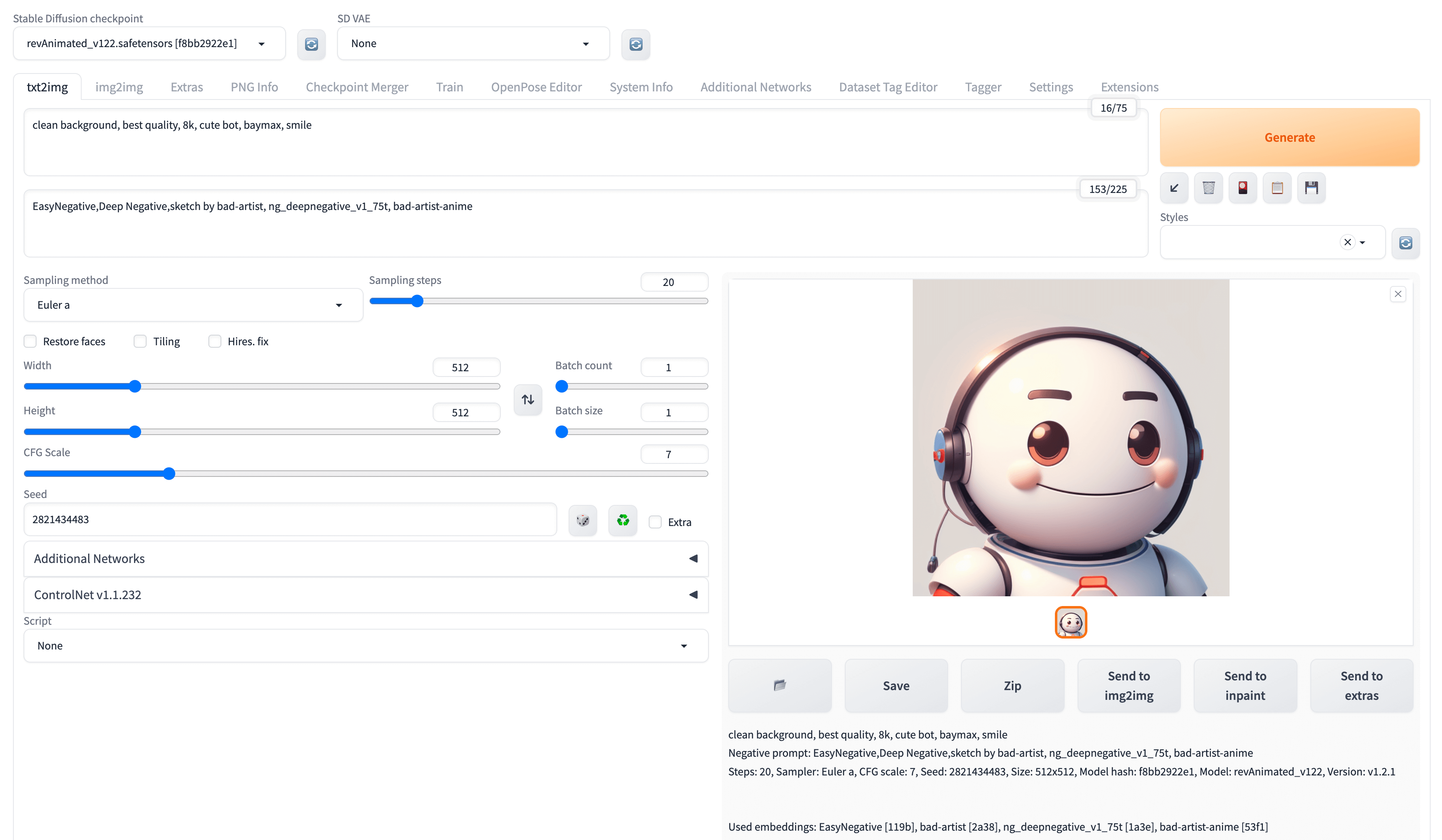
WebUI
常用文件架构
- models 存放SD模型、LoRA等文件
- Stable-diffusion:所有SD模型文件需要放置于该目录,SD模型下载地址见下文。
- LoRA:位于models/LoRa目录,全称Low-Rank Adaptation of Large Language Models。简单来说,SD是一个大模型(1GB+),LoRA就是一个小模型(100MB+),主要用于一个特定领域的微调,可类比成一个建立在基底大模型基础上的面向垂直行业的小模型,如盲盒LoRA可用于快速将图片风格转成盲盒风格,大家也可以根据需要自行炼制自己的LoRA模型。
- embeddings 文本嵌入,简单来说就是文本的压缩表达(即将文字变成数值以便计算机处理),在SD中,可通过embedding减少提示词的输入,提升提示的准确性,如SD经常出现一些NSFW、或者多余的手指头等情况,一般需要在负向提示词上屏蔽,常用的负向embedding库如EasyNegative,只需要输入EasyNegative即可大幅提升出图质量。
- extensions 插件目录,所有插件都需要放置于该目录。
以下将分模块讲解
模型
安装完sd-webui以后,还需要下载模型,才能真正运行任务,常用的模型网站来源如下
- HuggingFace:很多大公司或团体发布了大量的开源SD模型,如stabilityai、runwayml
- CivitAI:国内也称C站,上面有大量爱好者发布的模型、LoRA等,如revAnimated、Dreamshaper、Deliberate等
注意:C站有很多NSFW的内容,工作时间谨慎浏览。
以下列举常用的模型列表
- model
- LoRA
- 墨心 MoXin 水墨风
- blindbox/大概是盲盒 盲盒风
- hanfu 汉服 汉服风
- 沁彩 Colorwater 水彩风
- 墨心 MoXin 水墨风
插件
插件系统为SD添加了无限的想象力,所有插件位于extensions目录,以下列举常用的插件
sd-webui-controlnet
一开始尝试使用SD的时候,尝试希望用垫图img2img的方式完成画风转换,发现转来转去画面总会无法精确控制和原画的相似度,无论怎么设置权重也并不让其变得更好。
后来才发现原因是一直用midjourney的那套提示词公式(如-iw),而正确打开方式应该是修改img2img的denoising参数(下文有提到)。
而ControlNet的出现,也为画风迁移提供了新的路径。
openpose-editor
姿态编辑,如果画面主体出现预期外的动作,可以通过该插件修复。
sd-webui-openpose-editor
支持直接在ControlNet内编辑姿态。
additional-network
常用于LoRA训练后的模型选择,通过在X/Y plot,设置不同的权重+不同阶段的LoRA模型,挑选相对合适的LoRA模型。
枯燥的文字介绍完了,给大家看一下实际应用案例,希望对SD能有一个直观的认识:)
应用
为了演示,搜集了人物、自然风光、城市建筑等类别的照片,所有图片均来自于无版权网站Pixabay
文生图
参数
1 | boy, portrait, art, edge lighting, soft focus, 8k, best quality, 3d, blender, ultra high definition |
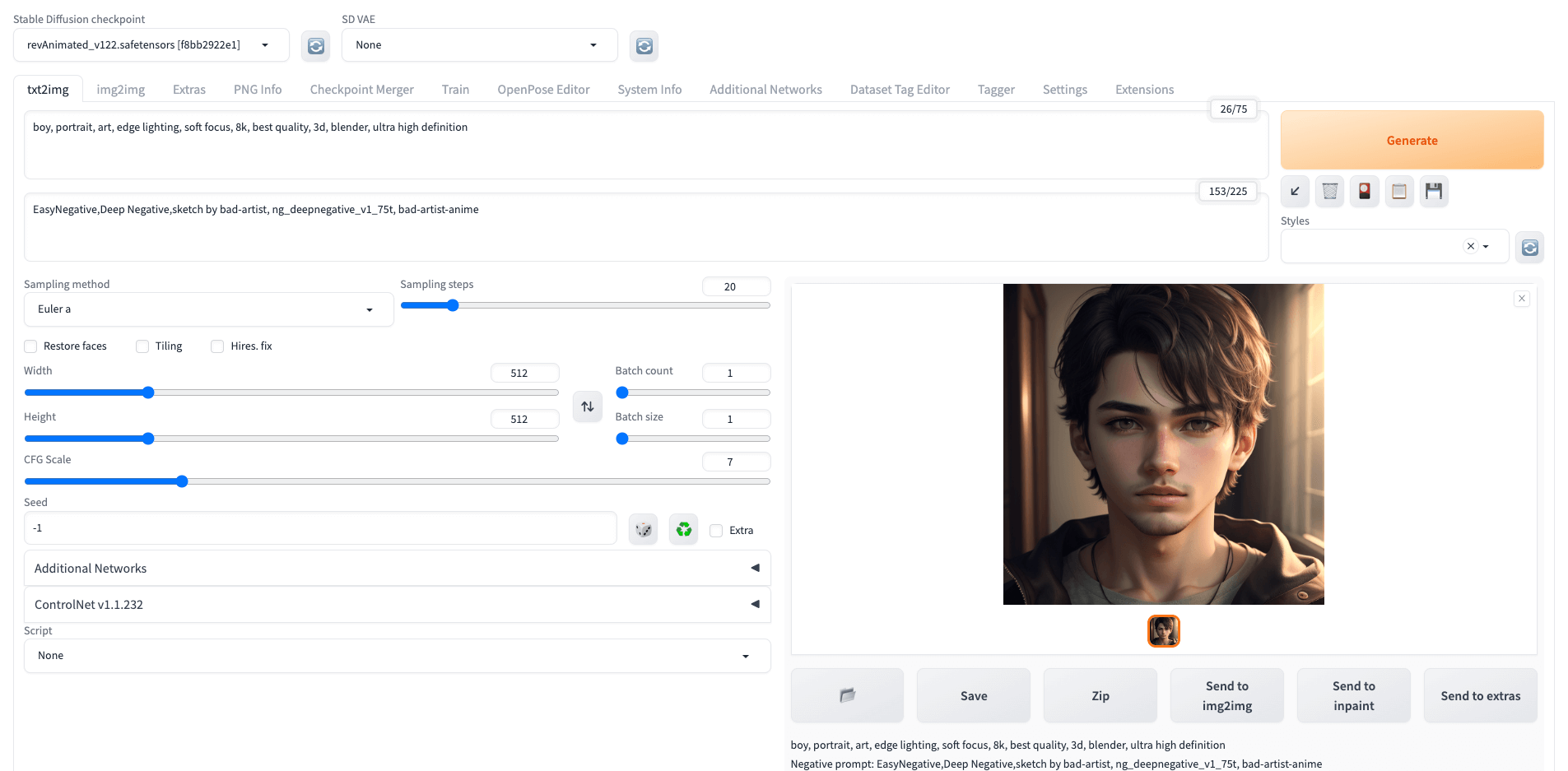
图生图
一般通过设置denosing参数控制生成图像和原图的近似程度,那么多大才合适呢?
可以有个简单的判断方法。
在Script下拉框打开X/Y/Z plot,X type选择denosing参数,输入0,0.2,0.4,0.6,0.8,1
参数
1 | clean background, best quality, 8k, Ghibli Style |

不难看出,denoising>0.6,SD就开始天马行空了:)
画风迁移(基于ControlNet)
下面介绍画风迁移的另一种途径,即基于ControlNet。
在txt2img页面,打开ControlNet,勾选Enable代表启用ControlNet,preprocessor预处理器选择canny,model选择control_canny。
之后就在提示词和负向提示词输入对应文字即可完成风格迁移。
人物
- models: revAnimated, Dreamshaper, Deliberate, GuoFeng3, Disney
- styles: ghibli style, makoto shinkai, lora:Moxin_10:0.5, lora:Colorwater_v4:0.5, lora:blindbox_V1Mix:0.6



风景
- models: revAnimated, Dreamshaper, Deliberate
- styles: ghibli style, makoto shinkai, lora:Moxin_10:0.5, lora:Colorwater_v4:0.5, lora:blindbox_V1Mix:0.6


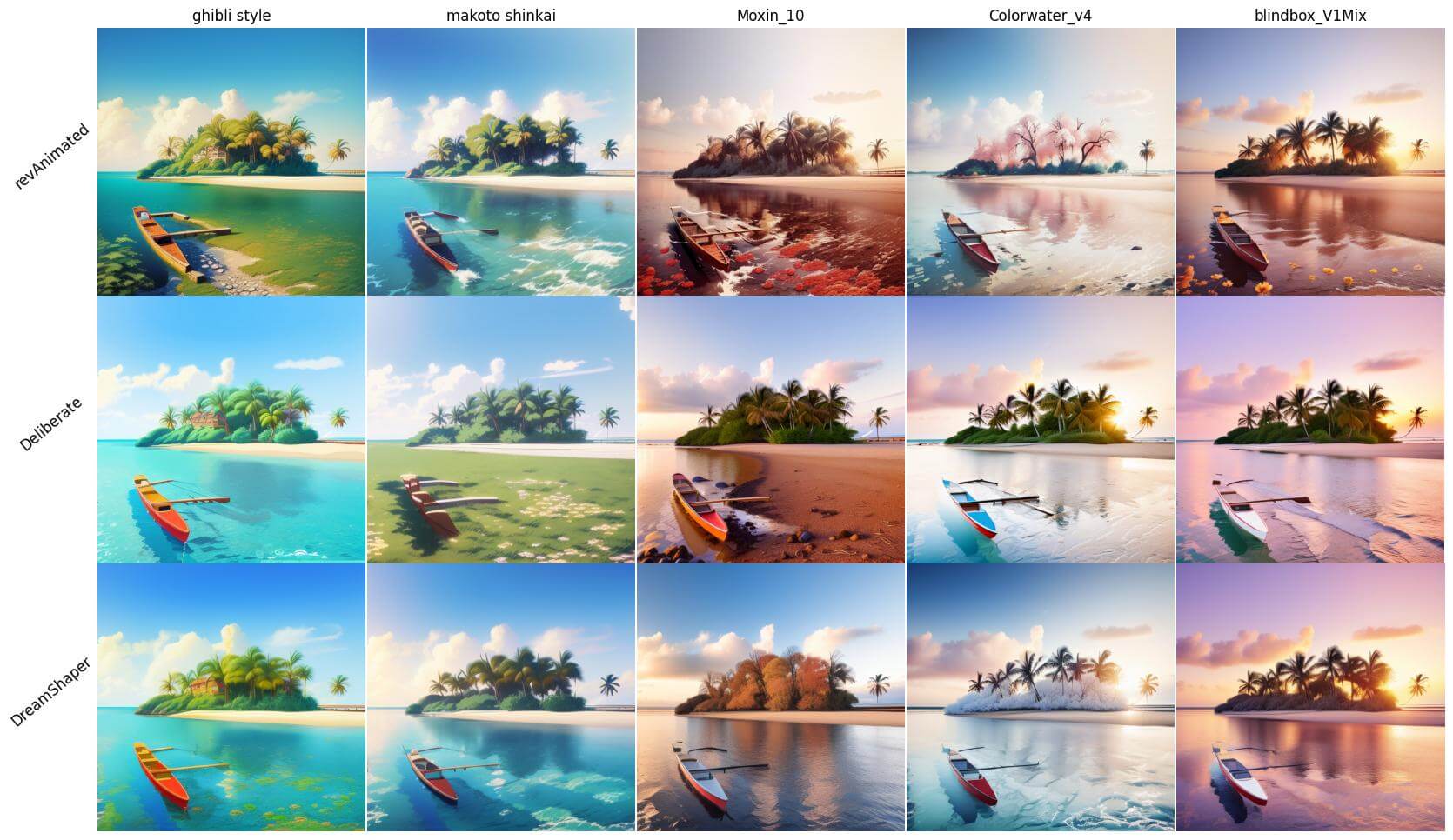
建筑
- models: revAnimated, Dreamshaper, Deliberate
- styles: ghibli style, makoto shinkai, lora:Moxin_10:0.5, lora:Colorwater_v4:0.5, lora:blindbox_V1Mix:0.6



图片超分(高清放大)
在Extras页面,选择对应的放大算法(如Lanszos、ESRGAN_4x、LDSR等)和放大倍数(如4)即可实现图片放大
这里我选择LDSR放大4倍,比较前后,发现人物脸部明显增加,不过也存在眼睛和嘴唇细节崩坏的情况,这种情况下再启用修复即可。
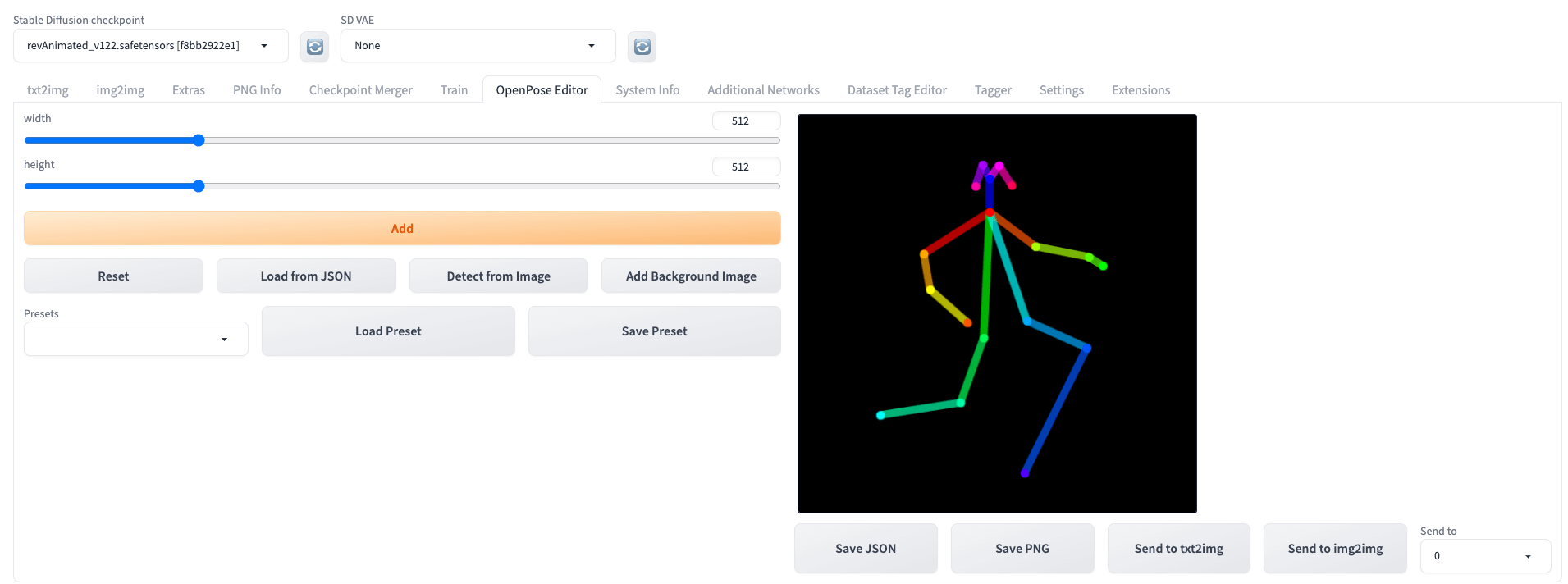
姿态调整(基于OpenPose Editor)
安装完OpenPose Editor插件后,找到对应Tab,编辑人物姿态,然后点击Send to txt2img/img2img即可实现与文生图/图生图的数据联动。
这里,以文生图为例,在原来文生图基础上,只是新增了OpenPose(注意preprocessor选择none,model选择control_openpose模型),即可实现人物姿态修改。
1 | boy, portrait, art, edge lighting, soft focus, 8k, best quality, 3d, blender, ultra high definition |
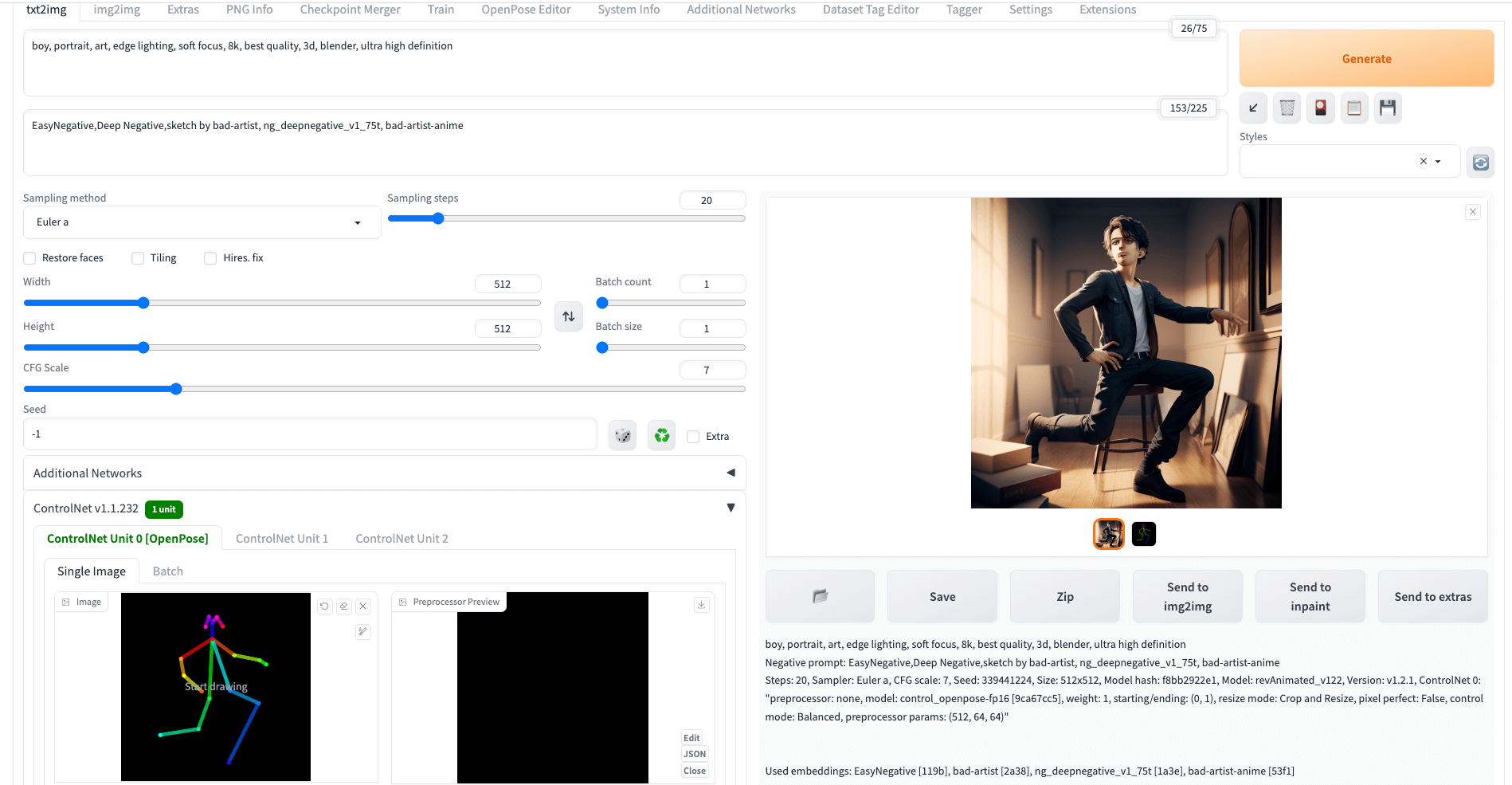
小结
本文简单介绍了SD的基础概念和常见的应用,旨在为未接触SD的朋友提供一个直观的认识,基于SD可快速实现之前需要熟悉PS等工具才能掌握的功能,极大地降低创作门槛。
- 风格迁移:既可以从img2img配合denosing参数、也可以配合txt2img配合ControlNet
- 姿态编辑:借助OpenPose Editor插件可实现人物姿态自由调整
- 图片超分:通过Upscale等工具实现图片放大
当然上述所列应用也都只是SD的冰山一角,后续可以根据自己需求搜索相应教程。