Quivr,官方自我介绍“你的第二个大脑”,可以简单理解成你的个人专属知识库,借助生成式AI的能力,让你的数据管理更加高效。
简介
特点
- 借助AI技术智能检索生成信息。举个例子,上传一份上市公司的年报,让Ta变成年报阅读理解机器人。
- 支持多种文件格式,如TXT、Markdown、PDF、Powerpoint、Excel、Word、Audio、Video等。
- 安全存储,租户隔离,不同用户数据不会混用。区别于其他公用平台,借助Quivr可以搭建个人专属知识库,上传私有数据,并与其对话。
- 代码开源,免费使用。
局限性
- 截至目前(20230610 v0.0.13),上传文档时不支持指定知识库,即用户所有的文档将放在同一知识库中。举个例子,知识库文件可能涉及领域A、B、C,如需单独检索领域A,目前可行办法是通过新建用户区分不同领域,将各自领域的知识库分别上传。
- 知识库大小限制:Quivr存储后端为Supabase,目前个人用户免费额度:数据库存储空间500MB,2个免费项目(免费项目如一周内无任何活动会被暂停),个人用一般够用。如需索引大型知识库,也可以考虑自行部署Supabase替换。
前置条件
- 系统已安装Docker、Docker Compose
- OpenAI Key(前述文章有提及无Key的解决办法)
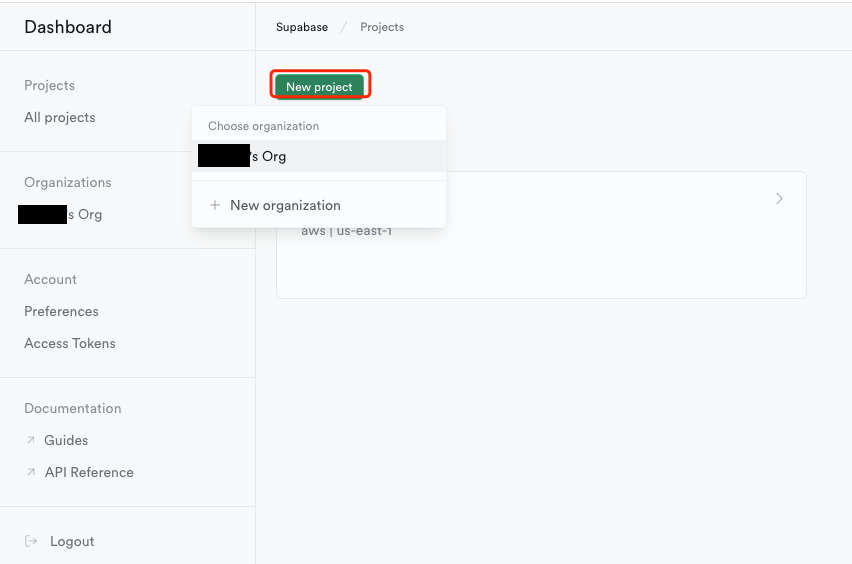
- Supabase:需要提前注册账户并创建项目,用于存储知识库文件,创建新项目如下图所示
部署流程
拉取代码
1 | git clone https://github.com/StanGirard/Quivr.git && cd Quivr |
修改配置
关键配置参考下面注释按需修改。
这里主要分成两大块,前端服务和后端服务。
前端配置
配置文件位于frontend/.env
1 | NEXT_PUBLIC_ENV=local |
supabase配置项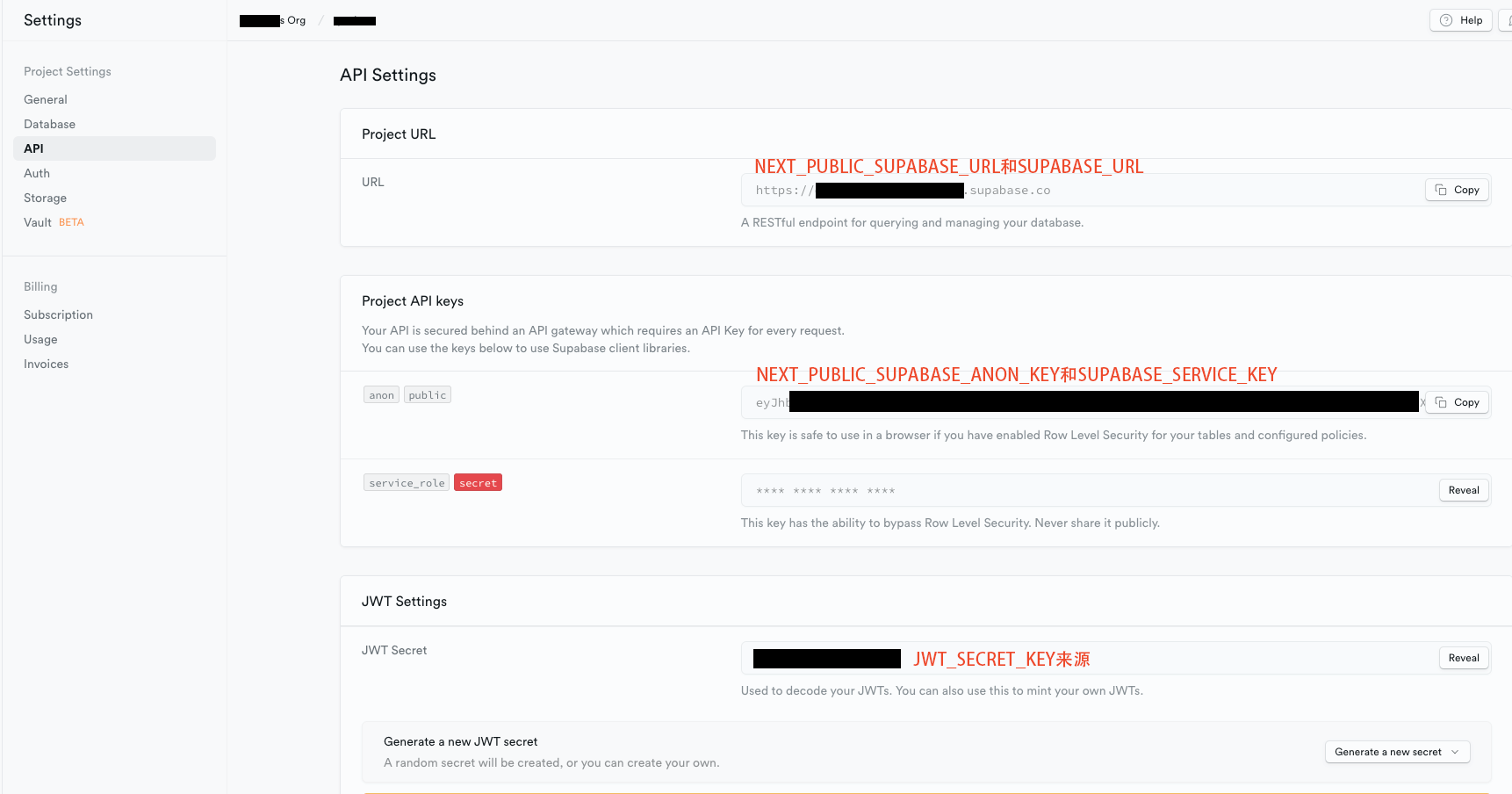
后端配置
配置文件位于backend/.env
1 | SUPABASE_URL=SUPABASE项目地址,同NEXT_PUBLIC_SUPABASE_URL |
初始化数据库
以v0.0.13为例,在Supabase的编辑框输入如下语句即可初始化数据库。
注:这里可能因版本迭代导致代码变更,建议追踪主页最新main分支。

1 | create extension if not exists vector; |
编译部署
编译镜像并部署服务,编译时间会有点长,可以先出去活动一下~
1 | docker compose -f docker-compose.yml up --build |
如果看到下列提示,代表部署完毕。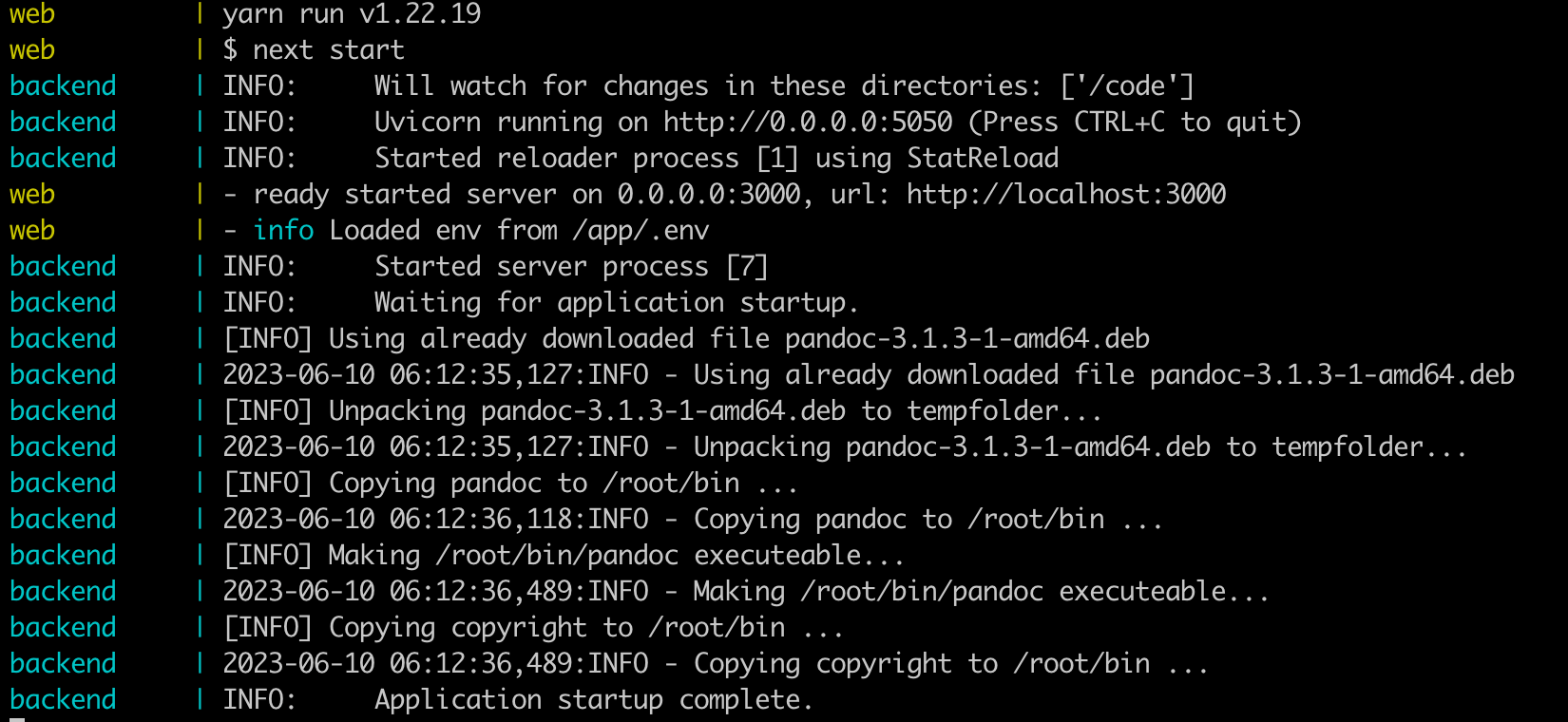
可以直接通过http://部署服务器IP:3000访问,如页面无法访问记得检查防火墙是否已打开3000端口。
效果展示
基于文档的问答
选择上海机场(600009)的2022年年度报告,截取了管理层讨论与分析章节的片段上传。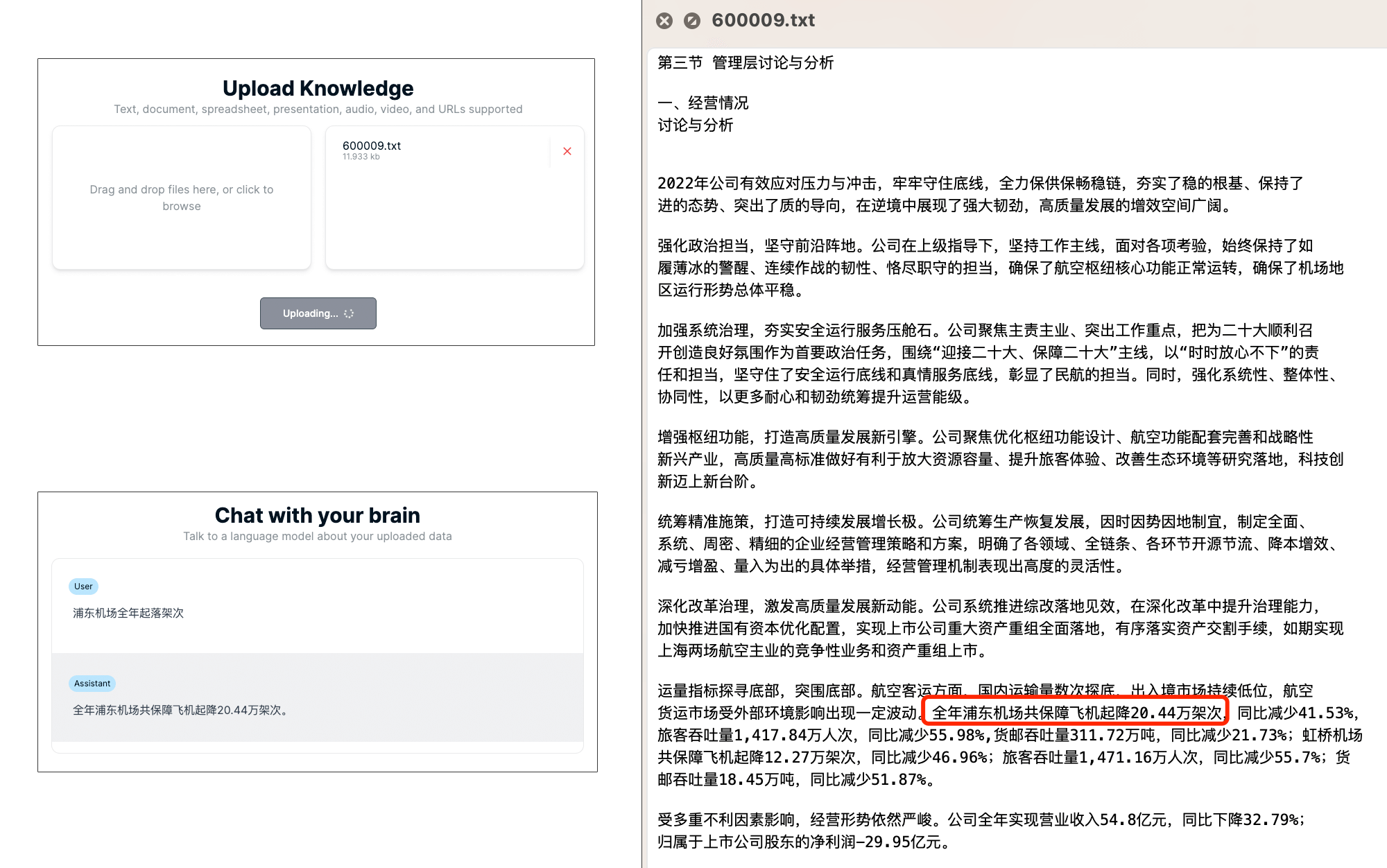
基于网页的问答
选择百度百科的某个页面让其分析,抽取关键信息。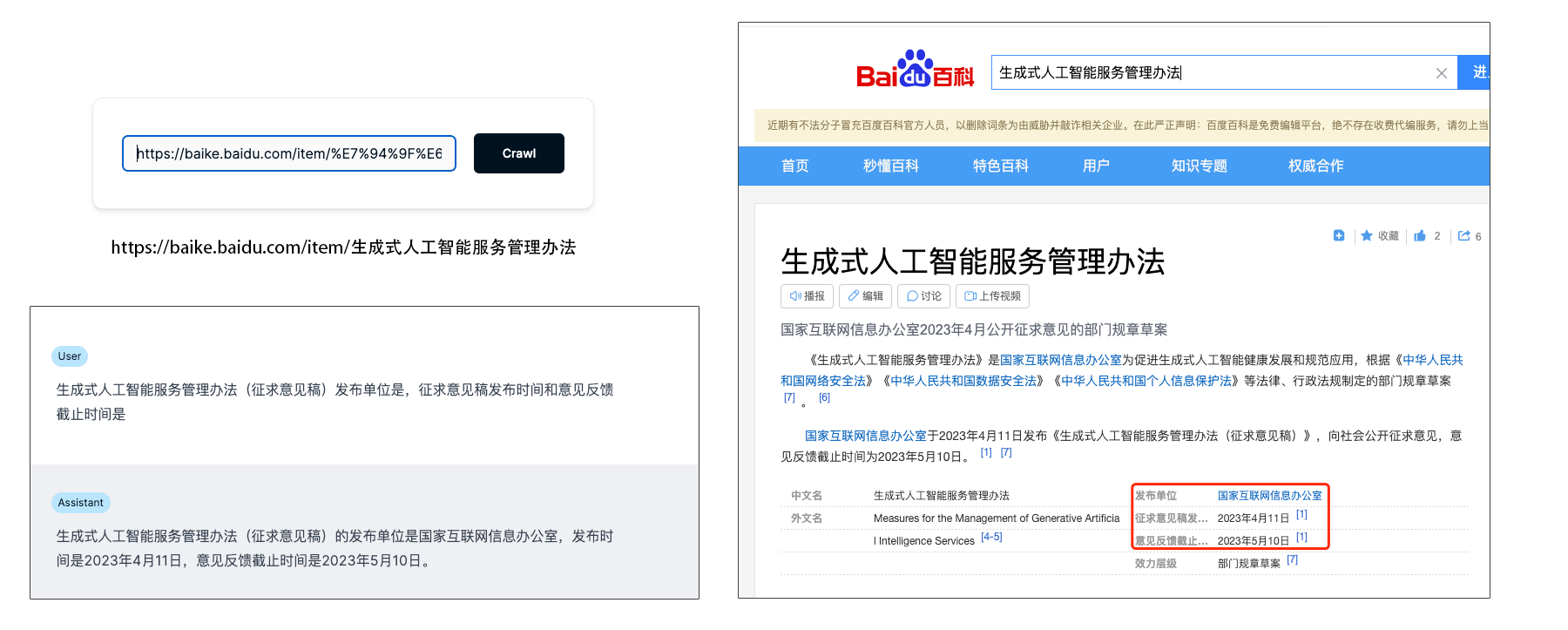
注意事项
- 如在远程服务器部署,千万记得修改
NEXT_PUBLIC_BACKEND_URL配置,否则会提示文档上传失败,因为默认上传服务器是localhost。 - 建议选择海外VPS服务器进行编译,因编译过程中需下载部分依赖,国内云服务器访问可能会超时。
- 低配VPS机器(如1核2G)如果在编译frontend镜像时报错
JavaScript heap out of memory,可以尝试如下办法- 增加虚拟内存,这里以CentOS为例
1
2
3
4
5
6mkdir -p /data/swap
FILE=/data/swap/swapfile_4g
dd if=/dev/zero of=${FILE} bs=1M count=4096
du -sh ${FILE}
mkswap ${FILE}
swapon ${FILE} - 修改frontend/Dockerfile文件,将
RUN yarn build替换成RUN NODE_OPTIONS=--max-old-space-size=4096 yarn build,这里4096是我随便写的值,按需填写,单位MB
- 增加虚拟内存,这里以CentOS为例
写在最后
Quivr部署步骤相较于前述文章手把手教你搭建私有GPT应用麻烦一些,不过官方文档写的还算清楚,虽然中间踩了一些坑,最后也算成功完成了整体部署。
如需咨询私有化部署事宜,可在公众号botflow1下方留言,提供一站式部署服务。